
Social Proof: A Tool for Determining Authority
In the Library with the Lead Pipe is pleased to welcome another guest
author, Steve McCann! Steve is a Digital Projects Librarian specializing in information architecture, usability studies, and data analysis.
By Steve McCann
In 2008, when I was visiting Anaheim, CA, for the ALA Annual Conference, I had a rather unpleasant experience renting a car. I had a reservation for the least expensive vehicle available (gas at that time was priced around $4 a gallon), but the salesman was insisting I upgrade to something larger. What sticks out in my memory was the tactic he was using, an influence technique called Social Proof which I had been reading about. His gambit was to point to an SUV on his pictorial list of available cars and emphatically state that “this is what everyone is renting here in Los Angeles.” This put me in an awkward position, since the idea that 100% of car rentals in LA were oversized SUVs was something I simply hadn’t considered previously. I found myself in a state of insufficient information and was suspicious that he was trying to take advantage of this. In fact, he was claiming authority on the subject of correct LA car rental procedures, and I could either accept his authority or go against “everyone” and rent a subcompact. It was a strange situation for a librarian to find himself, since I am, in general, much more likely to be navigating a state of “information overload.” If I had thought of it, I could have consulted my Internet friends via my cell phone and gotten a plethora of advice, but, in the end, I knew the whole idea was silly so I declined. Undeterred, he said his piece again, only this time much more loudly as if I couldn’t hear him. After declining a second time, I received a remarkable look of disgust, reminding me strongly of someone biting into a lemon.
I bring up this story because of the visceral power of this type of coercion. For me, it was patently obvious that he could not back up the claims he was making so, in a sense, I had it easy. His assertion lacked credibility at a gut level, and I really didn’t need to consult with anyone else. Reflecting on the situation, however, it became apparent that standing at the rental counter surrounded by unfamiliar people and asking for a vehicle was, in a way, analogous to the experience a patron has when visiting a reference desk for the first time. They obviously have an information problem and are looking for an authority of some kind. The main difference is that a reference librarian is trained to help patrons locate credible authorities in spite of a thicket of federated searches, Library of Congress call numbers, subject terms, and the spectrum of “article – journal – database” resources, among countless other difficulties. The librarian is an authority in her own right on the subject of research and generally recognized as such. The question this article seeks to ask is: to what extent can the library website framework, with all of its catalogs, vendors, guides, etc., become recognized as an authority in the subject of research? The assumption I am making is that library websites are not automatically deemed authorities by patrons in the same way that librarians themselves are. First, many of our patrons consult with more recognized authorities in the form of Google services, the home pages of journal titles, or even, maybe especially, other patrons. In this article I propose that what library websites are missing is evidence of “social proof.” I will then introduce a commercial service that is taking steps in this direction with regard to weblogs and finally brainstorm the type of changes that would be required to supply this evidence.
How We Recognize Authority
“What we’re dealing with now isn’t information overload […] it really is a filtering problem rather than an information [problem].” (Shirky, 2008)
“One of the criteria we use to filter information is credibility, or believability.” (Wathen, 2002)
Patrick Wilson (1983), in his book Second Hand Knowledge, makes the distinction between two types of authority, administrative and cognitive. The first has power to command, but the second has power to influence one’s thoughts. Thinking back on the earlier example of the rental car salesman, the reason I wasn’t influenced was because he simply wasn’t credible. As it turns out, credibility is a major component of cognitive authority along with trustworthiness, reliability, scholarliness, “officialness,” and authoritativeness (Rieh, 2002). If a person, entity, or idea can achieve an impression of quality in any of these six areas, then that entity can act as a cognitive authority. The important point is that credibility and authority are both perceptions: a recognition of a quality which, once made, will allow a person to place her trust in a figure of perceived authority. Once placed, that recognition labels a person or idea as someone who “knows something we do not know” and who “knows what they are talking about” (Wilson, 1983).
The question then becomes what factors influence this perception of cognitive authority? In the following list, Wathen and Burkell (2002) summarize the variables related to perception into five factors affecting credibility:
- Source material
- Expertise / Knowledge
- Trustworthiness
- Credentials
- Attractiveness
- Similarity
- Likeability / Goodwill / Dynamism
- Receiver of material
- Relevance
- Motivation
- Prior knowledge
- Involvement
- Values / beliefs / situation
- Stereotypes about source or topic
- “Social location”
- Message
- Topic / content
- Internal validity / consistency
- Plausibility of arguments
- Supported by data or examples
- Framing (loss or gain)
- Repetition / familiarity
- Ordering
- Medium of the material
- Organization
- Usability
- Presentation
- Vividness
- Context of the information
- Distraction / “noise”
- Time since message encountered
- Degree of need
What is striking about this list is that it is an awfully large number of judgments for a student to make. Working on the reference desk, it’s not uncommon for a student to say he or she has a paper due that day and needs three authoritative sources. The student in this situation is not going to conduct a systematic search but rather resort to a more primitive form of decision making, Social Proof.
The Power of Social Proof
“The individual can be conceptualized as a social actor, and information-seeking activities take place within a social community whose knowledge, characteristics, expectations, and norms are internalized within the individual. This may be especially relevant for young people, whose information seeking and learning is inherently social given the importance of social ties and networks during adolescence and early adulthood” (Rieh, 2008).
In Cialdini’s (1988) Influence: the Psychology of Persuasion, he talks about the enormous power of Social Proof. Here’s the cartoon version found on page 120 (it may remind you strongly of how Digg, Delicious, and other social tagging systems work):

Figure 1: The Powerful Affect of Similar Others on our Behavior (Cialdini, 1988)
According to Cialdini (1988), what’s going on in the image above is the “awesome influence of the behavior of similar others.” In other words, one important tool we use to decide how to act in a given situation is to look at what other people are doing. It may be that this is an evolutionary byproduct. For example, if someone stands up calmly in a crowded library computer lab and yells “fire!” and then sits down again, the chances are good that you will work your way through a checklist of credibility factors. Is the source credible? Is the information relevant to me? Is the message plausible? Was the presentation convincing? Isn’t this just juvenile noise? If the student who yelled goes back to work, then his credibility is suspect and evacuation is unlikely. However, if the two factors of uncertainty and similarity are at play, then credibility is judged very quickly. Uncertainty can be described as the state “when we are unsure of ourselves, when the situation is unclear or ambiguous[.] When uncertainty reigns, we are most likely to look to and accept the actions of others as correct” (Cialdini, 1988). Are people starting to leave the computer lab? If yes, then the perception of credibility just got a big boost. This perception is especially strong if the other people in the lab are viewed as similar to ourselves.
This behavior transfers quite well to the web. For example, in eye-tracking studies of marketing materials it is consistently shown that people look where other people are looking. The following heatmap images from a eye-tracking study shows this quite clearly (Breeze, 2009):

Figure 2: The Effects of Social Proof in Advertising
“Here’s the same 106 people looking at the second image for the same amount of time […] Notice how many more people are actually reading the text that the baby is looking at in the above image? Not to mention the increased attention on the brand!”
The reason this behavior is significant is because studies have shown people will read, at most, 28% of the words on a web page (Nielsen, 2008). The author of the above eye tracking study is saying that people are actually reading the text, but it’s clear that they are not reading the entire text. They are just skimming and keying in on certain keywords such as “chlorine-free” and “clinically.” In an eye-tracking heatmap like the one above, the more concentrated the colors over a text, the more time is being spent looking at that area of the screen. In short, marketers are able to manipulate the effects of social proof to force people to stop and read their copy.
But let’s return to the subject of library websites. How can we convince users to pay attention to factors of credibility? Library interfaces are largely text based. Take a look at most OPACs, and it’s clear that this type of short-circuiting of credibility judgments is not happening. Instead, libraries are relying on the users taking a laborious and systematic approach by judging between multiple credibility factors. In a sense this is wholly correct; librarians are invested in supplying the user with texts that are not only gratifying but also appropriate. Librarians are also invested in teaching the careful evaluation of the credibility factors of those sources. On the other hand, in the image above the marketer asserts the text the baby is looking at is the right text; the brand being presented is the right brand to satisfy the consumer’s information need. Librarians would not make such a claim because we recognize more than most the immense number of contextual variables involved. In this way library websites are largely designed around a contradiction: on the one hand we assert that a solution to an information need can be found within our domains; but on the other hand we refuse to make any judgments regarding the credibility of texts for our users. The question then becomes is this attitude a mistake? Is it not possible that some form of visual credibility ranking could be found to bridge this gap?
The PostRank Model
One company is combining the principles of social proof along with a more formalized approach to the ranking of credibility. The way they are doing it is instructive for librarians, even if the amount of data processing involved is daunting. As of this writing they are currently ranking the social proof for nearly 900,000 RSS feeds. The total number of individual weblog postings comes to approximately 1.6 million per day. For each of these feeds, they then track the social performance of each post relative to other posts within the same RSS feed. The social metrics used to calculate this performance they are calling the “Five C’s of Engagement:” Creating, Critiquing, Chatting, Collecting, and Clicking. The theory behind this is one of social proof: the more an individual weblog post is interacted with socially, the more attention it probably warrants. Figure 3 is an example of the PostRank score for recent articles published in Smashing Magazine, a usability and design weblog. Notice that low-scoring posts are grayed out, the good-scoring post is light orange (score = 5.6), and the best-scoring post is a dark orange. “Credibility” is immediately recognizable in the second post which scored a 7.3.

- Figure 3: Smashing Magazine articles filtered to show only “Good” postings.
When the user hovers over this score they are presented with a visual breakdown of the component factors that go into this credibility ranking (figure 4). Each factor represents a social activity score from PostRank’s “5 C’s of Engagement.”

- Figure 4: Breakdown of component factors that combined to create the PostRank score.
The implementation of PostRank scores is highly volatile, which has caused some to question its usefulness. For example, after checking the three PostRank scores 24 hours following the image capture of Figures 1 & 2, the scores had already changed. The company uses a moving temporal window in which all posts are calculated one against the other. An example of the effect this causes is if your weblog publishes a single post that is then “slashdotted” (i.e., suddenly wildly popular because of a mention in a high-traffic website) then all other posts in that temporal window will suddenly score extremely low because of the difference in social activity between the postings. This scoring discrepancy will remain until the temporal window passes the high-performing post, or until the low-performing posts themselves are supplanted by a new higher standard of performance. While this may or may not make sense from a business standpoint, from the user’s point of view rankings that jump around frequently affects the perceived “trustworthiness” of the ranking system.
Elements of Social Proof for Library Websites
If library websites were able to develop such a tool with which to rank the credibility / cognitive authority of all the intellectual content within their domains, what would it look like? Because of the librarian’s calling to provide access to, but not judgment of, the individual texts, it would have to take into account the credibility factors identified above. To work in the highly social environment of the web, the library website would also need to put the power of social proof into play. The website would need to be designed in a way as to allow patrons to quickly and visually identify the attention of “similar others.” In other words,the true cognitive authorities within any given subject. To meet these conflicting demands, the tool would need to provide feedback in the two areas where social proof is strongest: Uncertainty and Similarity.
To combat a user’s “uncertainty” when navigating between multiple source materials, our tool would need to show elements that assist in snap judgments. This would involve data that is superficial to the content of a work, or, according to Tseng & Fogg elements of presumed credibility and surface credibility (Tseng, 1999).
- Uncertainty Data Elements
- Citation counts and/or incoming links to a work
- Number of times a work was checked out or read
- Number of works an author has published in her career
- Number of comments attached to a work
- The attractiveness, likeability, and/or usability of the work’s format
To determine “similarity,” our tool would need to show elements that assist the user to make a judgment as to the cognitive authority of a work. This would involve source labels such as “PhD,” the title of the journal, the name of the publishing company, etc. Other similarity scores might include the experience other scholars had with the work or even personal ratings like what is seen in GoodReads. According to Tseng & Fogg, these elements would be composed of reputed credibility and experienced credibility factors.
- Similarity Data Elements
- Source impact factors of a title or journal
- Source rejection rate of a journal title or publisher
- Whether or not the work is refereed
- The total number of critical reviews
- The calculated quality of works citing the work in question
- The Library of Congress subject terms associated with the work
- Temporal groupings; an example might be a 10 year, 100 year, or adjustable window that affects all element calculations
- Total number of syllabi listings
- Total number of subscribers to a periodical title or holdings calculation for other works
- A user generated “thumbs up” or “thumbs down” ranking
The series of calculations involved for each title in the above factors could then be represented within a library OPAC or a periodicals database in a way similar to that of PostRank’s system. If it was built correctly it could be used to quickly and easily “drill down” to relevant cognitive authorities within any given research context. Of course there is a potential downside. The first is the immense amount of data that would have to be managed on an ongoing basis. The second, and perhaps more pressing, would be the problem of unintended consequences. Just because a piece of information is socially dynamic, doesn’t mean that it is correct or even helpful. A cautionary tale from the world of finance involves the below chart highlighting the financial bubble which peaked in 2006/2007. In figure 5, the analyst Barry Ritholtz (lower left) recognized early on that the fundamentals of the economy did not support the high valuation of stocks. He was proven correct, but not until the market collapsed in 2008/2009.
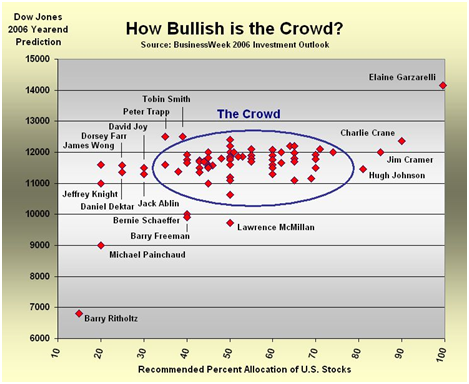
Figure 5: Herd Mentality Shown Among Analysts
This type of herd mentality is a hallmark of social proof. To make matters worse, there is no proof that the elements I’ve selected above would be the correct ones for the researcher’s information needs. It is uncertain whether such a credibility ranking system would lead to more harm than good.
Conclusion
In this article, I’ve attempted to brainstorm a method for raising the profile of library websites to the level of authority that individual librarians enjoy. To do this, multiple credibility factors will need to be addressed and social proof feedback will need to be implemented in some way. Despite its flaws, the PostRank model may provide guidance on how this could be accomplished. It would be calculation intensive and require iterative research to make sure it was not skewing patron’s sense of credibility within subject areas. But regardless of the difficulties, it may be helpful to remember what a statistics professor has said about relying upon models for guidance: all models are wrong, but some models are useful.
Thanks to Derik Badman, Jennie Burroughs, Ellie Collier, Donna McCrea, and Sue Samson for their assistance in reviewing and editing this article. Special thanks to Kim Duckett whose feedback on my earlier work on social proof and authority led me to write this article.Bibliography
Breeze, James. You look where they look | UsableWorld – James Breeze’s Blog. 3/16/2009 [cited 4/9/2009 2009]. Available from http://usableworld.com.au/2009/03/16/you-look-where-they-look/.
Cialdini, R. 2004. The science of persuasion. Scientific American Mind.
Cialdini, Robert B. 1988. Influence : science and practice. Glenview, Ill. Scott, Foresman.
Cope, William W., and Mary Kalantzis. 2009. Signs of epistemic disruption: Transformations in the knowledge system of the academic journal. First Monday; Volume 14, Number 4 – 6 April 2009. Available from http://www.uic.edu/htbin/cgiwrap/bin/ojs/index.php/fm/article/view/2309/2163.
Eastin, Matthew S. 2007. Toward a Cognitive Developmental Approach to Youth Perceptions of Credibility. The John D. and Catherine T. MacArthur Foundation Series on Digital Media and Learning -, 29-47.
Eysenbach, Gunther. 2007. Credibility of Health Information and Digital Media: New Perspectives and Implications for Youth. The John D. and Catherine T. MacArthur Foundation Series on Digital Media and Learning -, 123-154.
Flanagin, Andrew J., and Miriam J. Metzger. 2007. Digital Media and Youth: Unparalleled Opportunity and Unprecedented Responsibility. The John D. and Catherine T. MacArthur Foundation Series on Digital Media and Learning -, 5-27.
Harris, Frances J. 2007. Challenges to Teaching Credibility Assessment in Contemporary Schooling. The John D. and Catherine T. MacArthur Foundation Series on Digital Media and Learning -, 155-179.
Ito, Mizuko, et al. 2007. Foreword. The John D. and Catherine T. MacArthur Foundation Series on Digital Media and Learning -, vii-ix.
Jadad, A. R., and A. Gagliardi. 1998. Rating Health Information on the Internet Navigating to Knowledge or to Babel? Jama 279, no. 8:611-614.
Lankes, R. D. 2007. Trusting the Internet: New Approaches to Credibility Tools. The John D. and Catherine T. MacArthur Foundation Series on Digital Media and Learning -, 101-121.
Metzger, Miriam J., and Andrew J. Flanagin. 2007. Introduction. The John D. and Catherine T. MacArthur Foundation Series on Digital Media and Learning -, 1-4.
Nielsen, Jakob. How Little Do Users Read? (Jakob Nielsen’s Alertbox). in useit.com [database online]. May 6, 2008 [cited 4/9/2009 2009]. Available from http://www.useit.com/alertbox/percent-text-read.html.
Rieh, S. Y., and N. J. Belkin. 1998. Understanding judgment of information quality and cognitive authority in the WWW. Journal of the American Society for Information Science 35, 279-289.
Rieh, Soo Y., and Brian Hilligoss. 2007. College Students’ Credibility Judgments in the Information-Seeking Process. The John D. and Catherine T. MacArthur Foundation Series on Digital Media and Learning -, 49-71.
Ritholtz, Barry. Cult of the Bear, Part 1. in TheStreet.com. 2006 [cited April 14 2009]. Available from http://www.thestreet.com/_tscana/markets/marketfeatures/10260096.html.
Savolainen, R. Media credibility and cognitive authority. The case of seeking orienting information. Information Research: an international electronic journal 12.
Shirky, Clay. 2008. It’s Not Information Overload. It’s Filter Failure. Web 2.0 Expo 2008. New York, NY ed.O’Reilly Media, Inc. and TechWeb. Available from http://www.web2expo.com/webexny2008/public/schedule/detail/4817
Sundar, S. S. 2007. The MAIN Model: A Heuristic Approach to Understanding Technology Effects on Credibility. The John D. and Catherine T. MacArthur Foundation Series on Digital Media and Learning -, 73-100.
Wathen, C. N., and J. Burkell. 2002. Believe it or not: Factors influencing credibility on the Web. Journal of the American Society for Information Science and Technology 53, no. 2:134-144.
Weingarten, Fred W. 2007. Credibility, Politics, and Public Policy. The John D. and Catherine T. MacArthur Foundation Series on Digital Media and Learning -, 181-202.
Wilson, P. 1983. Second-hand knowledge: An inquiry into cognitive authority. Greenwood Pub Group.
Workman, M. 2008. Wisecrackers: A theory-grounded investigation of phishing and pretext social engineering threats to information security. Journal of the American Society for Information Science and Technology 59, no. 4.

This article is licensed under a Creative Commons Attribution-NonCommercial 3.0 United States License. Copyright remains with the author/s.
You missed the citation for Shirky’s information filtering quote in the bibliography. I was wondering if it was his “It’s Not Information Overload. It’s Filter Failure” talk at the Web 2.0 Expo last year. I wrote about that in my own blog. I’m asking because I’m interested to see if he developed this notion further than he took it in that presentation.
Thanks Peter, you’re right that is where I found the quote. We’ll try to get the post updated, but in the meantime here’s the citation:
Shirky, Clay. 2008. It’s Not Information Overload. It’s Filter Failure. Web 2.0 Expo 2008. New York, NY ed.O’Reilly Media, Inc. and TechWeb. Available from http://www.web2expo.com/webexny2008/public/schedule/detail/4817
It’s a great notion and I’m surprised he hasn’t published it anywhere (as far as I can tell).
Hi Steve,
What an engaging read — my compliments (and thank you for including PostRank). :) Particularly interesting to me since, as you can imagine, we spend a LOT of time talking among ourselves and with the user community about the nature of authority, influence, and engagement. Fascinating to be involved in an environment while we’re trying to write definitions for things we’re immersed in daily.
A couple of clarifications about how PostRank works. PostRank scores change quickly because the metrics are gathered/analyzed in real-time.
So when a post is just published, no one’s engaged with it yet, so it’ll score a 1.0. But as soon as people start engaging with it — comments, bookmarks, tweets, etc. — its score starts to rise (compared with the performance of other recent posts on the site).
If the scoring didn’t change with the metrics, the scores wouldn’t be accurate or very useful. And if they didn’t change very fast they wouldn’t be very useful to those who must regularly monitor.
Not to mention the fact that ~50% of posts’ engagement happens within the first 50 minutes post-publishing, and you can’t engage with your audience while the conversations are going on if you don’t know where and when.
Of course, at the same time, we don’t continue to check for metrics indefinitely, but have calculated an engagement curve to determine typical engagement velocity of posts.
Secondly, we’re definitely aware of the digg/slashdot/re-tweet/insert-your-own-viral-experience effect, and so have made sure to weight for it in our algorithms.
If we didn’t, as you noted, it would torpedo the rankings of posts in a similar time frame and would make the rankings about as balanced as me comparing my blog’s engagement to TechCrunch’s. (Which is why we don’t compare to other sites, either, in determining a site’s posts’ metrics.)
Hope that helps. If any of that isn’t clear, or you have any questions, feel free to let me know.
This might help explain the continuing disconnect between library USAGE and library FUNDING, as reported in the ALA’s most recent State of America’s Libraries report….
Thanks for the reference!
You present an interesting and complex perspective. I am keen to do some more thinking about this in order to create a set of guidelines on creating social media.
From the social perspective, it would seem that the perceived credibility of a person on Twitter, for example, strongly affects the likelihood that they would be followed. ‘Following’ someone is a judgement based on the follower/followed ratio, user profile text, presence of a profile link, the graphics of the Twitter profile page and content of the tweets visible on a the page at the time it is seen. Not to mention the fact that someone is well known then they are likely to get a lot of followers.
It is also interesting to note with Twitter, the herd mentality is not as simple as it seems. If you have a lot of followers/following then a judgement must be made on why this is so? Are you simply marketing or are you actually popular?
Pingback : Social Proof: A Tool for Determining Authority — cafedave.net
I’m coming to your post a month late now, but I just wanted to say a big thank you for this article!
The whole idea is fascinating to me. Do you have examples of library web sites/systems that are implementing any form of social proof at this point? Has anything been shown or are there any case studies that have been done for library sites or OPACs that have “favorites” or reviews enabled within the system?
This also reminds me of the EBay example of social proof. How do we choose from which vendor to purchase? Well, we choose those who have the best user ratings.
I understand you’re talking here about a more technological model of social proof, but the idea comes from the same place.
Great post!
Thanks Emily, I think you’re right about the EBay model of user ratings helping us decide levels of satisfaction. That’s social proof at it’s most elemental, imho. I don’t know of any libraries that are doing it with data, but with images many are (or should be). A quick Google Image search brings up the following examples of Cialdini’s “powerful influence of similar others”:
Smiling Subject Matter
Something to pay attention to
Physical research
Library website research
Busy public library
Busy academic library
Library as place
Really good “library as place”