
Spotlight on Digital Government Information Preservation: Examining the Context, Outcomes, Limitations, and Successes of the DataRefuge Movement
In Brief:
Access and preservation of online government data and information has been a long-standing and complex issue for librarians in government information librarianship, but it has recently started to receive attention on a larger level from the media, public, and libraries in general. The most recent initiative to archive digital government data was the DataRefuge movement in 2016 and 2017, which sponsored DataRescue events where people came together to capture static webpages and harvest dynamic online content for preservation purposes. This article examines the history and context of print and digital government information preservation initiatives and then focuses in on the DataRefuge movement to discuss its outcomes, limitations, and successes in light of long-term preservation and public access.
by Eric Johnson and Alicia Kubas
Introduction
When publicly useful datasets and information under government control are no longer freely available, when they are hidden, or when the public does not know they exist (or existed), those datasets are lost. The restriction of data availability can occur for many reasons, including political bias, temporary government shutdown, link rot, and routine redesigning of websites. In the worst case, not only access will be affected, but data collection itself may be halted. While some might view a reduction in data collection favorably, there are many datasets integral to research, improving health, mitigating crime, community building, and other areas important to improving quality of life in the United States.
While the loss of information can be considered a nuisance or inconvenience to people who use that information on a regular basis, there is a more significant consequence to creating political bias in available information. If information is no longer available to be read, our freedom to effectively govern our democracy is curtailed. “The right of free inquiry and the equally important right of forming their own opinions…is of the utmost importance to the continued existence of democracy…and that freedom of the press in all forms of public communication be defended and preserved” (Texas Library Association 2013). That includes not just political opinion statements, but also the data and information citizens can use to make informed decisions about political leaders as well as daily choices. For instance, knowledge about climate change can persuade a person to make personal behavioral changes as well as inform their decisions about local and national leadership.
Furthermore, government information is not just important to the general population: it is used by policymakers, academics, researchers, and many others for decision-making and critical discussion. The U.S. government collects, aggregates, and disseminates a large volume of information. The authors believe that this information should be freely available without bias based on political views or motivations.
Accessibility of information, including government information, has been of concern to libraries since their inception (although, unfortunately, there were times in their history where access was limited to certain groups of people). The term “free” library or “public” library shows a philosophical difference from private subscription libraries of the 1700s and 1800s. Localities decided to make books freely available to the populace, and thereby increase societal good (American Library Association n.d.). Libraries participating in the Federal Depository Library Program (FDLP), a program run by the U.S. Government Publishing Office (GPO) for federal publication dissemination to the public, agree to provide access to government publications and information free of charge to anyone who requests it.
Within the profession, librarians generally believe that freedom of information is essential (American Library Association 2006). Freedom of information is an extension of freedom of speech and is not only supported by the U.S. Constitution’s Bill of Rights, but by the Universal Declaration of Human Rights supported by 48 countries (United Nations n.d.). All of these ideas underscore librarians’ philosophy of universal access to information of all types, including data, and show why the topic of access to government information and data is so pertinent to libraries.
The presidential debates and political campaign statements in 2016 showed that one of the candidates scorned and rejected evidence that the world’s climate has been changing as the result of human activities. The New York Times reported that “Mr. Trump has called human-caused climate change a ‘hoax.’ He has vowed to dismantle the Environmental Protection Agency in almost every form.” (Davenport 2016). After President Trump was elected, information under his control and in conflict with his own viewpoints was seen to be at risk and of concern to the public. Consequently, scientists and concerned citizens began collecting and archiving data from government websites (Dennis 2016), and thus began the DataRefuge movement and its DataRescue events where academics, librarians, coders, concerned citizens, students, and many others developed new models of cooperation to assist in the collecting and archiving of government information. These events also helped raise awareness of the longstanding issue of online government information preservation. Libraries and other non-profit organizations contributing to this effort would then manage and provide access to that information into the future.
Within the context of DataRescue efforts and this article, government data is defined as data, metadata, and information under government control and generally accepted to be in the public’s best interest to be made publicly available. This includes data that is collected or created by the government, or required to be submitted to the government for public dissemination or organized access. The organization and access to data and summary information along with metadata that is provided by government websites is essential to retrieving and understanding the underlying data. This does not include sensitive or secure information.
To fully appreciate the efforts, goals, and impact of the DataRefuge movement and DataRescue events as well as the roles librarians can play, it is important to understand the context in which DataRescue was born. This article includes a brief history and current status of government information dissemination and access through the Federal Depository Library Program as well as current initiatives to make government information and data accessible long-term and preserved for public access. Throughout, we will discuss challenges and barriers to preservation and future access of digital government information and data that come up with each program or initiative. Finally, we will examine the impact as well as the limitations of DataRescue events and U.S. government data preservation as a whole.
Overview of the Current Landscape
The Federal Depository Library Program (FDLP)
Government information in the United States has been disseminated to the American people since 1813 when Congress authorized House and Senate Journals as well as other Congressional publications to be distributed to select universities, state libraries, and other organizations (McGarr 2000). Since then, the federal government has taken major strides forward in ensuring public accessibility of government information of all types and in all formats through the inception of the Government Publishing Office, formerly known as the Government Printing Office, and its public dissemination arm in 1895, which took up the role of the Federal Depository Library Program to deposit tangible government materials into depository libraries across the United States and its territories. The height of paper document dissemination by GPO was in the 1980s, when the number of publications distributed to depository libraries increased by more than one-third (U.S. Government Printing Office 2011). While this program seeks to disseminate to libraries all government information of public interest, there have always been documents, even in the print era, that have not been funneled through the program. What further complicates this issue is that federal agencies began to question the statutory authority and constitutionality of requiring agencies to contract with GPO for printing after a 1983 Supreme Court decision that called similar issues into question (Petersen 2017). Today, this continues to be a contentious issue with agencies deciding to skip over the GPO altogether in favor of other publishing means and providers. Naturally, this problem is even more dire in a digital-heavy publishing environment where dissemination and deposit does not occur through the FDLP. In an era of print, a category of participating depository libraries, called regional depositories, agree to retain all disseminated documents to ensure long-term access to tangible government documents.
With the era of electronic government information, the system became more complex. By the 1990s, government information had an electronic presence that eventually came under GPO’s purview with passage of the 1993 GPO Electronic Information Access Enhancement Act (Government Printing Office Electronic Information Access Enhancement Act of 1993 1993). GPO was then required to provide “a system of online access” to various prominent government publications deemed appropriate for electronic access by the Superintendent of Documents. A year later, GPO rolled out GPO Access, its database for online access to government publications–primarily Congressional materials–and thus began its efforts to provide permanent public access to online government materials published in conjunction with GPO. This does not mean that libraries were not still continuing to receive many publications duplicated in print or only available in a physical format. The push for online access was precipitated by a rising user preference for digital access as well as the cost-saving that digital publishing provided over print, and the publishing format was often decided by what would be the most inexpensive to produce (McGarr 2000). By the 2000s, many depository libraries were moving towards digital access instead of tangible access precipitated by a variety of factors, including user preference, availability of publications in print, and availability of physical space in libraries. This phenomenon was also reflected in the decline in tangible publication distribution through the FDLP: 12.2 million in 2000 to 3.2 million in 2009 (U.S. Government Printing Office 2011). Today, depositories that receive few to no print documents are becoming more common, and the amount of tangible distribution of government publications is declining as many agencies are publishing exclusively online content.
Although GPO Access provided a major step forward in public access to electronic government information, by the early 2000s an update was needed. In 2009, GPO’s Federal Digital System, or FDsys, was released to the public. This new system offered an improved interface for online access to mostly post-1996 Congressional and Executive government publications, both digitized and born-digital, and it also served as an archive for long-term preservation and access to this digital content. In 2016, GPO unveiled govinfo.gov, its newly redesigned beta interface, for improved user experience and enhanced functionality with a purpose to “ingest, authenticate, preserve, and to provide version control to the information products of the Legislative, Judicial, and Executive branches of the U.S. Government” (U.S. Government Publishing Office, Office of the Superintendent of Documents 2017, 6). With the overall move to a majority of government publications being published digitally without being deposited in libraries but rather linked from a local catalog to GPO’s catalog or system, digital preservation and access has become a prominent concern for GPO, the depository community, and users.
Born-Digital Government Information and Data
It is clear that GPO has a vested interest in preservation of digital information, whether digitized from a physical copy or born-digital, although they have limited statutory authority to act on this interest. One of the major problems, though, is that GPO can only preserve the publications and information that it receives from federal agencies and organizations. The failure of many agencies to submit all of their published or distributed information is a long-standing problem for GPO. In a 1996 report, GPO had already identified notification and compliance from agencies as a major issue in the context of a more electronic government landscape: “With the increasing emphasis on electronic dissemination and decreasing compliance with statutory requirements for agencies to print through GPO, identifying and obtaining information for the FDLP is becoming increasingly difficult” (U.S. Government Printing Office 1996, ii). Another major concern is the cost-saving move to reduce publishing of government products through GPO in general. Today, access to agency publications has become more difficult as the landscape is almost exclusively digital and more agencies are simply posting data, reports, and information on their webpages and not submitting any content to GPO to be disseminated or archived.
To assist with this problem, GPO has a Document Discovery Program where lost or fugitive documents–online or tangible materials published by a federal agency that were not distributed through GPO–can be submitted for potential inclusion in GPO’s catalog and the FDLP (Medsger and Webb 2016). These are usually instances where the agency has posted a report on its website believing that decision is compliant for public access, when federal mandate also requires agencies to submit this information to GPO. Organized access to these materials by depository libraries and their preservation becomes more tenuous the more disaggregated they become, especially as digital publishing of federal publications continues to increase. In 2012, federal agencies published approximately 92% of government publications in a digital format (Federal Depository Library Program 2012, sec. 13.3), and today this is likely much higher with only a relatively small amount still published in print since the Obama administration’s call for expanded digital offerings of agency information in 2012 (Office of Management and Budget, The Executive Office of the President 2012).
While government-collected data and databases are included in the FDLP’s purview (U.S. Government Publishing Office, Office of the Superintendent of Documents 2017), data portals and raw datasets are content which GPO itself does not actively preserve nor deposit to depository libraries for local preservation. The U.S. federal government is the largest collector of data in the world, making this a wealth of information to which the public does not have guaranteed long-term access. Mistakenly, some assume that the bulk of this published data is accessible via data.gov, the federal government’s open data portal, but this is a metadata portal without hosting capabilities or preservation practices for the data itself. GPO does, however, archive some government webpages that are in scope of the FDLP and not duplicated in print, although it is not clear that this is done in a consistent or comprehensive manner (Dahlen 2017). Furthermore, they are not able to capture content that is not easily crawled or imaged, like video, datasets, portals, and other more complicated information types. This overall issue is why libraries, both depository and non-depository, as well as others, have turned their attention to this daunting problem through various initiatives and efforts.
Initiatives to Preserve or Replicate Government Information
With the many issues and gaps in existing efforts by GPO or federal agencies to provide long-term public access to born-digital government data, a variety of libraries, consortia, federal agencies, and others have stepped up to make progress in finding a solution to this large and complex issue of preservation of digital federal government data. The initiatives discussed below have worked on this issue in a variety of ways. Some have sought to archive individual webpages while others have focused on content specific to GPO’s online systems. Still others are seeking to raise awareness and advocacy towards the issue which is a step forward in finding more interested parties and resources to assist with this growing problem. The efforts are ordered chronologically from their inception to show the progress that has been made and built upon throughout the last decade.
LOCKSS-USDOCS
One partnership that has been active for many years is the LOCKSS-USDOCS network, a privately-run network also known as the Digital Federal Depository Library Program. This network began working on replication of digital federal content in 2010, building on the work done by libraries already using LOCKSS to preserve documents harvested from GPO Access between 1991 and 2007 (Jacobs and Reich 2010).
LOCKSS stands for “lots of copies keep stuff safe” and this is the main principle on which this Stanford-developed preservation network leans. The LOCKSS-USDOCS private network consists of 36 libraries, universities, the Library of Congress, and GPO, each of which host copies of ingested digital content from GPO’s FDsys (LOCKSS n.d.).
A major advantage to this model is that access is always guaranteed to member libraries in the case of a government shutdown during which GPO’s servers may be offline; the disappearance of digital content from government websites; or tampering with authenticity of a document (Jacobs and Reich 2010). However, the downside is that access is limited to those libraries that are LOCKSS members in the USDocs private network; it is free to be a member of LOCKSS-USDOCS if a library is already a member of the larger LOCKSS community, which requires a fee based on institution size and affords access to a variety of preserved content on top of government documents (LOCKSS n.d.). However, there is an option to join LOCKSS-USDOCS without being a member of the LOCKSS group, and this entails a smaller fee to cover support costs (LOCKSS Program n.d.). Although this initiative is admirable in working to mirror GPO’s FDsys content for future public access, it has not been able to address born-digital content on agency websites that has not been funnelled through the FDLP, and it is only available to those who are members.
End of Term Projects
There are a variety of initiatives underway to preserve government information and data for future public access, with the End of Term Project being one of the first. This collaboration among the Library of Congress, California Digital Library, University of North Texas Libraries, Internet Archive, George Washington University Libraries, Stanford University Libraries, GPO, and the public nominated 11,382 web pages from executive, judicial, and legislative government sites to “harvest and preserve” around the conclusion of the presidential administration ending on January 20, 2017 (Federal Depository Library Program 2016; University of North Texas 2016). It actually took several months to capture the data.
Previous end of term web collections are available at the End of Term Web Archive with collections for 2009 and 2013. The information collected is meant to be an archive of web pages and has expanded to include some of the underlying datasets (End of Term Web Archive 2016). However, these datasets have not been comprehensively captured in the past. The disadvantage to this project is that it cannot capture dynamic data from backend databases since they are not directly exposed on the internet. To access that data, typically a web form is filled and submitted and the server uses those parameters to query a database. The results are displayed on another web page. Downloading the whole underlying database is difficult or impossible. To programmatically access the data through the web requires someone to analyze the website’s database interface and program a tool to methodically query for data from that database.
Preservation of Electronic Government Information (PEGI) Project
The Preservation of Electronic Government Information (PEGI) Project is a new venture into digital government preservation which brings together information professionals from universities and federal agencies, including GPO and the National Archives and Records Administration. They recommend an environmental scan and a registry of what data are being collected and preserved (Halbert 2016). In addition, the PEGI Project will focus on stakeholder outreach and awareness through national forums to be held in 2018 and funded by an IMLS National Leadership Grant (Preservation of Electronic Government Information Project n.d.). Overall, the goal is to educate and take measure of the overall status of government data preservation and then make recommendations for future work in this area.
DataRefuge Project by University of Pennsylvania Program in the Environmental Humanities (PPEH DataRefuge Project)
The DataRefuge project was a collaboration between the PPEH, Penn Libraries, the Environmental Data & Governance Initiative (EDGI), and other groups concerned with climate change data that in 2016 launched what they called DataRescue events. These events consist of downloading and archiving at-risk data into a refuge, or repository, mirrored in multiple locations (PPEH Lab-DataRefuge 2016). The collaboration focused on addressing five concerns about federal climate and environmental data:
- What are the best ways to safeguard data?
- How do federal agencies play crucial roles in data collection, management, and distribution?
- How do government priorities impact data’s accessibility?
- Which projects and research fields depend on federal data?
- Which datasets are of value to research and local communities, and why?
On top of these concerns, one of the most difficult and tedious issues in an initiative like this is keeping track of the chain of custody of the data–namely, “where the data comes from originally, who copied them and how, and then who and how they are re-distributed” (Allen 2017). This would not be an issue for content that is preserved and made accessible by the originating authority, but for any harvesting done by an external actor it is an important concern. DataRefuge points to this as the “cornerstone” of the entire initiative. Documenting how data were archived preserves integrity, ensures verifiability, and contributes to the overall usability of the data in the future. Trying to predict how data may be used in the future and by whom is tricky at best, but consulting with those who already use data can help those preserving this data to do an optimal job of creating metadata for future users.
The collaborators kept these larger issues in mind when they created the event workflow and social network to help facilitate DataRescue events to nominate and download datasets for preservation. Nominated websites were copied into the Internet Archive–a non-profit digital library with more than 15 petabytes of information (Internet Archive n.d.). After more than 200 terabytes of government website data were downloaded, the next step was to create metadata records and provide access to the data in the DataRefuge repository (Environmental Data & Governance Initiative 2017). The focus of the DataRefuge project has also expanded to suggesting other possible event ideas to help communities build data durability (PPEH Lab- DataRefuge 2017d).
PPEH, EDGI, and their partners made an attempt to crowd source identification and collection of government information. They assisted in the collection of large amounts of information by creating and modifying data collection workflows. Collected webpage data are available from http://eot.us.archive.org/search/ using keyword searches. Additional descriptive metadata and indexing are being created to facilitate access when browsing by government agencies (Bailey 2017).
After the large wave of DataRescue events swept the country, the momentum continued with a meeting of representatives from universities, research libraries, federal agencies, repositories, academic consortia, non-profits, and other stakeholders in Washington, D.C., in May 2017 to discuss the next steps towards a larger scale approach to this initiative. This meeting of the nascent Libraries+ Network culminated in a report summarizing the events of the meeting, but unfortunately, no significant progress has been made by the group, with the most recent activity a blog post from June 2017 (Libraries+ Network 2017).
DataRescue Events
While there was concern for data preservation prior to the Trump administration coming into power, data loss occurrences immediately after the inauguration prompted organizations such as the Humane Society of the United States (HSUS) to act. For example, the Washington Post reported on February 3, 2017, that animal welfare data had been removed from the U.S. Department of Agriculture (USDA) websites, which included inspection reports on the treatment of animals at labs, zoos, breeding operations, and other sites (Brulliard 2017). In response, the HSUS notified the USDA that it would initiate legal action (Wadman 2017). The USDA responded that the website change was not the result of the new presidential administration, but just an ongoing website review. On August 18, the Public Search Tool for Animal Welfare Act compliance records was reinstated to the USDA website (USDA APHIS n.d.). Some organizations reacted to the threat of removed data by hosting “DataRescue” events (Harmon 2017).
Beginning in Toronto in late December 2016, and followed by Philadelphia, Chicago, Indianapolis, Los Angeles, and Ann Arbor in January 2017, the DataRescue movement continued across the country with many universities sponsoring and organizing events. The number of public events peaked in March 2017.
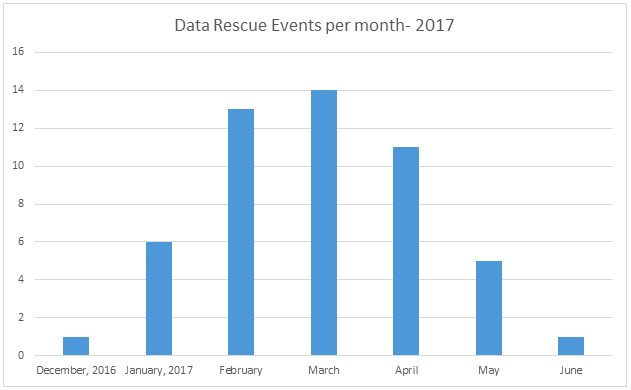
The number of DataRecuse events per month, December 2016-June 2017 (graphic created by the authors)
More than 50 events were publicized on the PPEH website, and nearly 200 newspaper and magazine articles were published related to DataRefuge, with 173 listed as of September 18, 2017 (PPEH Lab- DataRefuge 2017b, 2017c). The events were spread across the United States with a concentration around the coasts and the Midwest (PPEH Lab- DataRefuge 2017a).

A map of DataRecuse locations (graphic created by the authors)
After downloading hundreds of datasets and thousands of webpages, the work continued with cataloging the rescued data. Metadata needed to be created to make the data findable. PPEH DataRefuge organized a workflow for making data uploaded to the DataRefuge repository accessible (PPEH Lab- DataRefuge 2017e).
DataRescue Limitations and Challenges
It is difficult to determine the success of the DataRescue movement, and indicators of success may lie in the organizers’ goals for each DataRescue event. Many event organizers reported the number of websites they archived or gigabytes of data downloaded (Torres-Saez 2017), but much of the data downloaded is still available on government websites.
The motivations for government website changes are difficult to ascertain, and this makes the issue more complicated because there is no one root cause for disappearing data. Broken links and modified text can happen without malice or intent as institutions routinely re-organize their websites for a variety of reasons. However, each administration has policies that agencies are expected to follow. One summer intern on a communications team at the EPA was asked to draft tweets they could post to promote environmentally friendly lifestyles. She was also instructed, “Don’t mention climate change or going ‘green.’” Links to EPA’s information on climate change had become dead and she wondered, while policies may change, “could science, based on years of research, really become outdated, too?” (Miller 2018). No matter what the cause of data disappearance, the need still remains to make preservation copies of data so that they can be accessed by future researchers.
Additionally, it will take time for downloaded data and websites to be indexed and made fully available. There were terabytes of data downloaded during the events, and it is not clear if all of that data made it through the curation phase to be placed in the DataRefuge repository. Additionally, deficiencies in the data because of how the data were collected may not be obvious until later.
Another challenge is that by the time the DataRescue movement was in full swing, it was already too late and critical data may already have gone missing without anyone realizing it. Not being able to get to the data at the source (i.e., federal agencies) causes this problem and is an inherent issue in the DataRescue workflow.
The most glaring downside of the DataRefuge initiative and DataRescue events was the questionability of the accomplishment of long term preservation of government data. The main goal of DataRescue was to save government data for the future if it ever disappears. However, viewing the datasets indexed and archived in the DataRefuge repository through a lens of data curation for reuse and long term usability finds the metadata and documentation generally lacking for preservation purposes. Much of this can be ascribed to the workflow itself, which emphasized chain of custody and authenticity of the data over usability of the data and the ability to understand the context of the data if the website where it resided is gone in the future. The goal of the initiative was to save the data, and the curated datasets can indeed be found in the DataRefuge repository, but the larger picture of long-term use was not addressed. Part of this issue is relying upon community-driven work completed by individuals who do not have the expertise of data curation and understanding of archival practices.
Public outcry around this issue occurred because of a fear and concern for the disappearance of government data, and this is why events spurred such interest and coverage from the media. DataRescue attendees had a feeling of productiveness and accomplishment in contributing to this cause and felt satisfaction with the initiative taken up by DataRescue organizers and groups. Even though attendees of these events were fulfilled at the idea of contributing to this lofty goal, it is akin to the feeling of contributing to a charity for the sake of making oneself feel good and then ignoring the fact that much more needs to be done to solve the problem.
Furthermore, only a fraction of government data was harvested. EDGI reported 63,076 pages were seeded during DataRescue events to the Internet Archive using their Chrome extension and workflow, with 21,798 of these pages containing datasets or other dynamic content. While this is positive at a surface level, over 194 million unique URLs were captured for the EOT 2012 through human-contributed URLs and web crawlers that automatically snapshot the pages (Phillips and Tarver 2016). It would be nearly impossible for humans to go through every agency webpage looking for dynamic content or datasets that need to be specially harvested for preservation.
Lastly, this initiative has come to a standstill after its wave of initial interest and involvement from stakeholders, leaving no overall systemic plan to continue these efforts into the future. Frankly, federal agencies are not currently empowered by the current presidential administration to work on this issue with well-meaning academics and non-profits.
Positive Outcomes of DataRescue
Despite the lack of meaningful preservation efforts under the DataRefuge banner, the opportunity for a library to showcase its services and its ideals was valuable. Furthermore, depending upon participants’ roles in the event, each person likely had different takeaways and appreciations for the goals of DataRescue. For example, those nominating pages to the Internet Archive or End of Term Project could see the vast amount of government information and the many different types of information the government publishes, which gave librarians working with government publications collections an opportunity to speak about their role in government and civic literacy, preservation of historical print government content, and to promote research and reference services. Many libraries that hosted these events were also able to get positive press coverage about these efforts and highlight their roles in civic and community engagement. This is especially important to those that are land-grant universities with their “democratic mandate for openness, accessibility, and service to people” (Association of Public and Land-Grant Universities 2012). Highlights in the local newspaper, student newspaper, local radio, and even national print and radio media were widespread during the height of the DataRescue events early in 2017. While these events did not precipitate a deep shift in government data preservation, they are a step in the right direction to raise awareness of the issue.
In addition, DataRescue events gave university libraries a reason to collaborate with other campus groups and external partners. This most often included a digital humanities group, political science and government departments, environmental advocacy groups, and open data and hacker groups, among others. A few events included companion events such as speakers, workshops, discussions, and teach-ins. For example, at the two-day DataRescueDC event at Georgetown University, one day focused on a round table discussion about open data and data vulnerability as well as a teach-in focusing on the importance of climate data while the second was spent on data archiving. Both talks featured speakers and guests from around campus as well as the outside community (DataRescueDC 2017).
The additional context around government transparency was another positive outcome of these events. Encouraging civil engagement and literacy in light of what the federal government can do with access to information was also important. At NYU’s DataRescue event in February 2017, Jerome Whitington from NYU showed changes to the EPA website which removed the text “and mitigate[d] the effects of climate change” from a section on waste water energy use (Phiffer 2017). Starting these sorts of discussions and highlighting the overall issue of access to government information were the successes of these events, even if long-term preservation was not achieved with this movement.
Conclusion
Regardless of the limitations of the DataRefuge project and DataRescue events, this initiative brought widespread awareness to this complex and longstanding issue. The need to create a historical record of government websites and protect access to data between and during every presidential administration is still important, as this data will continue to disappear through a variety of means including government shutdowns, broken links, and policy changes. As organizations gain more experience and funding, the processes for pre-emptive collection and metadata creation are becoming more sophisticated; in the future this will hopefully pay off, although partnering with federal agencies would be the most ideal step forward in getting ahead of the problem.
There is a need for more institutional support through organized, well-funded programs and tasking the GPO with perpetual archiving and access to all public government data and websites. With this in mind, there is also a need for advocating for adequate funding for GPO to do this work. While there is no one answer to this overwhelmingly complex issue, it is clear that libraries in particular view this issue as an opportunity to contribute their expertise and resources in making forward progress towards solving this problem. Although there are many private, non-profit organizations that can help with the issue of disappearing or inaccessible government data and information, many libraries and librarians are uniquely positioned as publicly-funded and public-focused centers that have vested interest in these efforts because of their overall mission to provide universal access to information. Even though the DataRefuge movement did not precipitate a long-term solution or continue its momentum, there is no way to succeed in addressing this problem without making some attempts and seeing what happens. Even if some of those attempts are less than successful, sometimes it is the missteps that pave the way for more successful endeavors.
Acknowledgments
Many thanks for the insight and feedback from reviewers Shari Laster and Denisse Solis, and publishing editor Amy Koester.
References
Allen, Laurie. 2017. “Data Refuge Rests on a Clear Chain of Custody.” PPEH Lab. February 1, 2017. http://www.ppehlab.org/blogposts/2017/2/1/data-refuge-rests-on-a-clear-chain-of-custody
American Library Association. 2006. “Library Bill of Rights.” Text. Advocacy, Legislation & Issues. June 30, 2006. http://www.ala.org/advocacy/intfreedom/librarybill
———. n.d. “Social Role of the Library | Libraries Matter.” http://www.ala.org/tools/research/librariesmatter/taxonomy/term/143
Association of Public and Land-Grant Universities. 2012. “The Land-Grant Tradition.” http://www.aplu.org/library/the-land-grant-tradition/file.
Bailey, Jefferson. 2017. “2016 End of Term Web Archive,” November 30, 2017.
Brulliard, Karin. 2017. “USDA Abruptly Purges Animal Welfare Information from Its Website.” Washington Post, February 3, 2017, sec. Animalia. https://www.washingtonpost.com/news/animalia/wp/2017/02/03/the-usda-abruptly-removes-animal-welfare-information-from-its-website/
Dahlen, Ashley. 2017. Time Machine for Federal Info – Using Web Archive Content… WebEx streaming video. http://login.icohere.com/connect/d_connect_itemframer.cfm?vsDTTitle=Time+Machine+for+Federal+Info+-+Using+Web+Archive+Content…&dseq=18332&dtseq=108454&emdisc=2&mkey=public1172&vbDTA=0&viNA=0&vsDTA=&PAN=2&bDTC=0&topictype=standard+default+linear&vsSH=A#.Wfeav_w6VfI.gmail
DataRescueDC. 2017. “DataRescueDC.” DataRescueDC. 2017. https://www.google.com/maps/d/viewer?mid=1CMAmsh9st7u9p3l2C4Z5k9VZ_PE
Davenport, Coral. 2016. “Donald Trump Could Put Climate Change on Course for ‘Danger Zone.’” New York Times, November 10, 2016, sec. Politics. https://www.nytimes.com/2016/11/11/us/politics/donald-trump-climate-change.html
Dennis, Brady. 2016. “Scientists Are Frantically Copying U.S. Climate Data, Fearing It Might Vanish under Trump.” Washington Post, December 13, 2016, sec. Energy and Environment. https://www.washingtonpost.com/news/energy-environment/wp/2016/12/13/scientists-are-frantically-copying-u-s-climate-data-fearing-it-might-vanish-under-trump/
End of Term Web Archive. 2016. “U.S. Government Websites.” End of Term Web Archive: U.S. Government Websites. 2016. http://eotarchive.cdlib.org/
Environmental Data & Governance Initiative. 2017. “Archiving Data.” EDGI (blog). May 2017. https://envirodatagov.org/archiving/
Federal Depository Library Program. 2012. “Federal Depository Library Handbook.” https://www.fdlp.gov/file-repository/historical-publications/federal-depository-library-handbook/2252-final-version-of-the-fdl-handbook
———. 2016. “End of Term Presidential Harvest 2016.” September 1, 2016.
Government Printing Office Electronic Information Access Enhancement Act of 1993. “Public Law 103-40, 107 Stat 112-114.” June 8, 1993. https://www.gpo.gov/fdsys/pkg/STATUTE-107/pdf/STATUTE-107-Pg112.pdf.https://www.fdlp.gov/news-and-events/2693-end-of-term-presidential-harvest-2016
Halbert, Martin. 2016. “Digital Preservation of Federal Information Summit: Reflections.” Report. Digital Preservation of Federal Information Summit, April 3-4, 2016, San Antonio, Texas. April 2016. https://digital.library.unt.edu/ark:/67531/metadc826639/
Harmon, Amy. 2017. “Activists Rush to Save Government Science Data — If They Can Find It.” New York Times, March 6, 2017, sec. Science. https://www.nytimes.com/2017/03/06/science/donald-trump-data-rescue-science.html
Internet Archive. n.d. “Internet Archive: Digital Library of Free Books, Movies, Music & Wayback Machine.” https://archive.org/.
Jacobs, James R., and Victoria Reich. 2010. “Preservation for All: LOCKSS-USDOCS and Our Digital Future.” Documents to the People (DttP) 38 (3). https://freegovinfo.info/files/lockssusdocs-dttp38(3).pdf
Libraries+ Network. 2017. “May Meeting — Libraries+ Network.” May 8, 2017. https://libraries.network/may-meeting/
LOCKSS. n.d. “Digital Federal Depository Library Program | LOCKSS.” https://www.lockss.org/community/networks/digital-federal-depository-library-program/
———. n.d. “How to Join | LOCKSS.” https://www.lockss.org/join/
LOCKSS Program. n.d. “The LOCKSS Program, Digital Federal Depository Library Program, Frequently Asked Questions.” https://www.lockss.org/locksswp/wp-content/uploads/2012/03/Digital-Federal-Depository-FAQ.pdf
McGarr, Sheila M. 2000. “Snapshots of the FDLP (August 2000).” August 2000. https://www.fdlp.gov/about-the-fdlp/mission-and-history/2500-snapshots-of-the-fdlp-august-2000
Medsger, Melanie, and Ben Webb. 2016. “Poster Presentation: Wanted – Fugitives, Lostdocs, and Document Discovery at GPO.” In Depository Library Council. Arlington, VA. https://www.fdlp.gov/file-repository/outreach/events/depository-library-council-dlc-meetings/2016-meeting-proceedings/2016-dlc-meeting-and-fdl-conference/2796-poster-presentation-wanted-fugitives-lostdocs-and-document-discovery-at-gpo
Miller, Katie. 2018. “Perspective | As an EPA Intern, I Was Barred from Mentioning Climate Change.” Washington Post, January 3, 2018, sec. Outlook Perspective Perspective Discussion of news topics with a point of view, including narratives by individuals regarding their own experiences. https://www.washingtonpost.com/outlook/as-an-epa-intern-i-was-barred-rom-mentioning-climate-change/2018/01/02/acd991d2-ecb7-11e7-b698-91d4e35920a3_story.html
Office of Management and Budget, The Executive Office of the President. 2012. “Digital Government: Building a 21st Century Platform to Better Serve the American People.” https://obamawhitehouse.archives.gov/sites/default/files/omb/egov/digital-government/digital-government.html
Petersen, R. Eric. 2017. “Government Printing, Publications, and Digital Information Management: Issues and Challenges.” 7–5700, R45014. Congressional Research Service. Congressional Research Service. https://www.everycrsreport.com/reports/R45014.html
Phiffer, Dan. 2017. “Grabbing Government Data Before It’s Destroyed.” February 14, 2017. https://source.opennews.org/articles/data-rescue/
Phillips, Mark, and Hannah Tarver. 2016. “End of Term Publications Metadata Guide.” 2016. https://docs.google.com/document/d/1tx7D1QeptXhrTWEnph-PY_ON5JFO2CdnbBnCqlDU31Y/edit
PPEH Lab- DataRefuge. 2016. “DataRefuge.” PPEH Lab. November 2016. http://www.ppehlab.org/datarefuge/
———. 2017a. “Data Rescue Events.” 2017. https://www.google.com/maps/d/viewer?mid=1_4Q4-h_Z19SnhwIwv5xsRDd6X-4&hl=en
———. 2017b. “DataRefugePress.” PPEH Lab. 2017. http://www.ppehlab.org/datarefugenews/
———. 2017c. “DataRescue Events.” PPEH Lab. 2017. http://www.ppehlab.org/datarescue-events/
———. 2017d. “DataRescue Workflow.” PPEH Lab. 2017. http://www.ppehlab.org/datarescueworkflow/
———. 2017e. “Clean Up Datarefuge.Org.” PPEH Lab. 2017. http://www.ppehlab.org/unzipping-datarefuge/
Preservation of Electronic Government Information Project. n.d. “Objectives.” PEGI Project. https://www.pegiproject.org/objectives/
Torres-Saez, Joan. 2017. “Data Rescue Boulder Saved Actual Science Data, Lots and Lots of Data.” March 9, 2017. https://www.linkedin.com/pulse/data-rescue-boulder-saved-actual-science-lots-joan-torres-saez
United Nations. n.d. “Universal Declaration of Human Rights | United Nations.” http://www.un.org/en/universal-declaration-human-rights/index.html
University of North Texas. 2016. “Nomination Tool: Project URL Nomination.” 2016. http://digital2.library.unt.edu/nomination/eth2016/
U.S. Government Printing Office. 1996. “Study to Identify Measures Necessary for a Successful Transition to a More Electronic Federal Depository Library Program.” June 1996. https://www.gpo.gov/fdsys/pkg/GOVPUB-GP3-83702f16b5d4a3823308c2c477545669/pdf/GOVPUB-GP3-83702f16b5d4a3823308c2c477545669.pdf
———. 2011. “Keeping America Informed.” U.S. Government Printing Office. https://www.gpo.gov/fdsys/pkg/GPO-KEEPINGAMERICAINFORMED/pdf/GPO-KEEPINGAMERICAINFORMED.pdf
U.S. Government Publishing Office, Office of the Superintendent of Documents. 2017. “Public Policy Statement 2016-1: Scope of Government Information Products Included in the Cataloging and Indexing Program and Disseminated Through the Federal Depository Library Program.” https://www.fdlp.gov/file-repository/about-the-fdlp/policies/superintendent-of-documents-public-policies/2739-scope-of-government-information-products-included-in-the-cataloging-and-indexing-program-and-disseminated-through-the-federal-depository-library-program
———. 2017. “GPO’s Sysem of Online Access: Collection Development Plan.” https://www.fdlp.gov/file-repository/about-the-fdlp/gpo-projects/trustworthy-digital-reports/2930-final-systemcolldevplan-09302017
USDA APHIS. n.d. “USDA APHIS | AWA Inspection and Annual Reports.” https://www.aphis.usda.gov/aphis/ourfocus/animalwelfare/sa_awa/awa-inspection-and-annual-reports
Wadman, Meredith. 2017. “Updated: USDA Responds to Outcry over Removal of Animal Welfare Documents, Lawsuit Threats.” Science | AAAS. February 6, 2017. http://www.sciencemag.org/news/2017/02/updated-usda-responds-outcry-over-removal-animal-welfare-documents-lawsuit-threats
Hi! Please update the link to the DataRescue DC page: https://datarefuge.github.io/datarescue-dc/. The description of the events is also out of order (Day 1 – teach in, Day 2 – data archiving). Thanks!
The article has been updated to reflect these changes.
Hi folks. thanks for writing. Preservation of govt information is of critical importance. May I clarify your description of LOCKSS-USDOCS? The term “private” is just to differentiate these projects from the Global LOCKSS Network and simply means a group of libraries that use the LOCKSS software for a specific type of collection (govt documents, theses, data etc). While the project began by harvesting and collaboratively preserving the content on GPOaccess, we have continued to harvest GPO content as they’ve evolved their content management system from GPOaccess to FDsys to govinfo.gov. We collect and preserve *everything* on GPO’s system. There are 40+ collections, most of which span early 1990s – present while some (eg Treasury Dept docs and the Bound Congressional Record) go much further back. (see https://www.govinfo.gov/app/browse/category/bills-statutes).
And a clarification on how the software works: LOCKSS works with a permission statement posted to a site which tells the software that the content on the site may be collected. Getting every one of the 440+ executive agencies and commissions to grant permission is a near impossibility, which is why I’m extremely supportive of GPO efforts to ingest executive branch information, which will allow us to expand the amount of executive branch documents collected and preserved. The software is meant for preservation, but the content is made freely and openly available to the public (not just to LOCKSS-USDOCS members) if/when there’s a “trigger event” — like a journal publisher going out of business.
Sorry, but one more clarification is needed in terms of the End of Term Web harvesting project. EOT has now been done at the end of each of the last 3 presidential administrations starting in 2008. the latest (2016) harvest was put together by a combination of seed (url) lists collated from official sources (like USA.gov and the General Services Administration list of official .gov domains) and then filled in with seed nominations from the public. We had 15,000+ nominated seeds from 400+ nominators (via the UNT form) and over 100,000 seeds nominated from DataRescue/EDGI events/tools. This time around, we collected about 300 TB of data total (including ~130 TB of .gov ftp site archiving) which comprised @ 310,000,000 web URLs + 12,000,000 ftp files. Please see this presentation by Jefferson Bailey and myself at SJSU library school on May 1, 2017 for more info and background on End of Term (http://bit.ly/SJSU_eot_2016).
Pingback : Spotlight on Digital Government Information Preservation: Examining the Context, Outcomes, Limitations, and Successes of the DataRefuge Movement – The Idealis
The focus on the FDLP program here is a bit perplexing to me. To situate and contextualize the landscape of government information in the last several years means at least acknowledging the role (at least statutorily, if nothing else) of the National Archives and Records Administration in the rules concerning the records of executive agencies. The lack of discussion in this article of NARA’s role in developing the regulatory framework for government records is really disappointing. To my knowledge, much of the records that are created by agencies like EPA and DOI are affected far more by NARA’s actions (and sometimes inaction) than the aims of the FDLP.
Finally, the article would have also benefited from a discussion of the Obama-era OSTP office policy of open government. While there are very good critiques on how the Open Government Directive came up short on many counts, the original 2009 era directive did provide one of the better blueprints for building on in the interest of proactive disclosure of government data.